Power BI Data Modeling: A Complete Guide to Star Schemas
By Alex Gunnerson
Turn messy, oversized Power BI tables into fast, user-friendly star schemas with this step-by-step Power Query guide.
You've heard it countless times: "Always use a star schema in Power BI!" And for good reason, it's the gold standard for performance, usability, and scalability in analytical models. However, what's often glossed over is the gritty reality faced by many analysts: your upstream data rarely arrives in that pristine dimension/fact structure. More often than not, you're wrestling with massive, denormalized "mega tables", single, wide files that throw all your data into one colossal bucket.
This post will cover what a star schema is, why it's essential, and then, crucially, how to transform those unwieldy, denormalized datasets into a powerful star schema using Power Query as your essential tool.
What Exactly is a Star Schema and Why Do You Need One?
At its core, a star schema is a data modeling approach where your model tables are categorized into two distinct types: dimension tables and fact tables. This structure resembles a "star," with a central fact table surrounded by multiple dimension tables.
Dimension Tables: Think of these as your descriptive tables. They provide context to your data, answering the "who, what, where, when, and why" of your business events. For instance, a DimProduct table might describe product names, categories, and brands, while a DimDate table would contain year, month, and day details. These tables typically have a key column for unique identification and other columns used for filtering and grouping data in your reports.
Fact Tables: These are the heart of your analytical model, storing observations or events. Fact tables contain numerical values (facts) that can be aggregated, such as sales quantities, revenue figures, or production counts. They also include foreign key columns that relate back to your dimension tables, linking the events to their descriptive context.
The advantages of adopting a star schema in Power BI are numerous and impactful:
Optimized Performance: Power BI report visuals naturally generate queries that filter, group, and summarize data. A star schema, with its clear separation of dimension (filtering/grouping) and fact (summarization) tables, aligns perfectly with this query pattern. This leads to significantly faster query execution and snappier reports.
Enhanced Usability: By clearly separating descriptive attributes from measurable facts, your data model becomes much easier for users to understand and navigate. Business users can intuitively find the information they need to filter and analyze.
Flexibility and Extensibility: A well-designed star schema allows for easy expansion. As your reporting needs evolve, you can add new dimensions or facts without major overhauls to your existing structure.
Reduced Data Redundancy: Dimensions are stored once and linked to fact tables, minimizing data duplication and ensuring data consistency.
Creating a Star Schema in Power BI
There's no specific 'star schema' property or button in Power BI. Instead, you create a star schema by structuring your data into distinct dimension and fact tables, and then establishing the appropriate relationships between them. Typically, the 'one' side of a one-to-many relationship points to a dimension table, and the 'many' side connects to a fact table.
Your fact table will house the measurable events and the keys linking them to your descriptive dimensions. It's crucial to keep this table as narrow as possible, containing only what's necessary for calculations and relationships.
Duplicate Your Source: In the Power Query Editor, locate your SalesData query in the "Queries" pane. Right-click it and select "Reference." This creates a new query that is dependent on SalesData. Name this new query FactSales. Referencing is generally preferred over duplicating because any changes or updates to your initial SalesData query will automatically flow down to FactSales.
Remove Dimension Attributes: In your FactSales query, go to the 'Home' tab and click 'Choose Columns'. In the dialog box that appears, select ONLY the columns that represent measurable values (e.g., Quantity, UnitPrice, SalesAmount) and the keys that will link to your dimension tables (e.g., OrderID, OrderDate, CustomerID, ProductID). Clicking 'OK' will simultaneously remove all other descriptive columns, trimming your fact table to its essential components.
A Note on Multiple Fact Tables: It's important to understand that a star schema can, and often does, include multiple fact tables. These fact tables can share common dimensions. For instance, you might have FactSalesand FactReturns tables that both link to DimCustomer and DimProduct. This allows you to analyze different business processes while leveraging the same consistent dimension data. We'll focus on a single fact table for this example, but keep in mind that multi-fact designs are a natural extension of the star schema.
Creating Your Dimension Tables - Adding Context to Your Data
Dimension tables provide the "who, what, where, when, why" to your facts. They should contain unique entries for each descriptive attribute.
Create Duplicates/References for Each Dimension: Go back to your original SalesData query in the "Queries" pane. For each distinct entity you want as a dimension (e.g., Customer, Product, Date), right-click SalesData and select "Reference." Rename these new queries DimCustomer, DimProduct, and DimDate.
Shape Each Dimension Query:
DimCustomer:
In the DimCustomer query, keep only the CustomerID and all customer-related descriptive columns (e.g., CustomerName, CustomerCity). Remove all other columns.
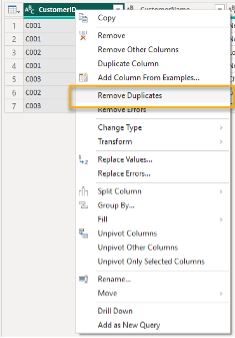
Crucially, select the CustomerID column, go to the "Home" tab in the ribbon, and click "Remove Rows" -> "Remove Duplicates." This ensures each customer is listed only once.
DimProduct:
Similar to DimCustomer, in the DimProduct query, retain ProductID and all product-related descriptive columns (e.g., ProductName, ProductCategory). Remove other columns.
Remove duplicates on the ProductID column.
Ensure Data Types: Before proceeding, review all columns in your fact and dimension tables and ensure they have the correct data types (e.g., SalesAmount as Decimal Number, OrderDate as Date, CustomerID as Text or Number, depending on your data).
Finalizing Your Power Query Setup: Disabling Source Load
This is a critical step for an efficient and performant Power BI model. If you leave the original SalesData table set to load into the Power BI model after you've used it to create your FactSales, DimCustomer, DimProduct, and DimDate tables, you would be loading redundant data. This leads to increased model size, higher memory consumption, and slower refreshes.
To prevent this:
In Power Query Editor, navigate to the "Queries" pane on the left side.
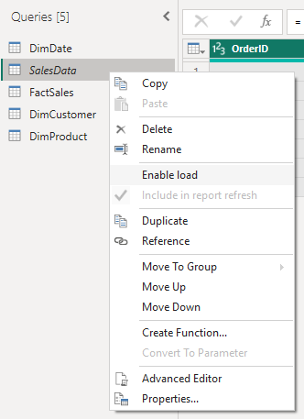
Locate your original, denormalized SalesData query. Right-click on SalesData.
From the context menu, uncheck the option "Enable Load".
Observe the Change:
You'll notice the text for SalesData in the "Queries" pane will become italicized. This indicates that the query is enabled for refresh and can be referenced by other queries, but its output will not be loaded as a table into the Power BI data model.
When you click "Close & Apply" after this, only your FactSales, DimCustomer, DimProduct, and DimDate tables will be loaded into your Power BI model. They draw their data from the SalesData query's processing steps, but SalesData itself doesn't become a visible, loadable table in your final model. This ensures efficiency and a clean, optimized star schema.
Load to Model and Establish Relationships
Once all your tables are cleanly structured in Power Query, it's time to load them into the Power BI data model and establish the vital connections.
Close & Apply: In the Power Query Editor, click "Close & Apply" on the "Home" tab. This loads your FactSales, DimCustomer, DimProduct, and DimDate tables into the Power BI Desktop data model.
Navigate to Model View: Once loaded, go to the "Model view" (the icon resembling three interconnected tables) in Power BI Desktop.
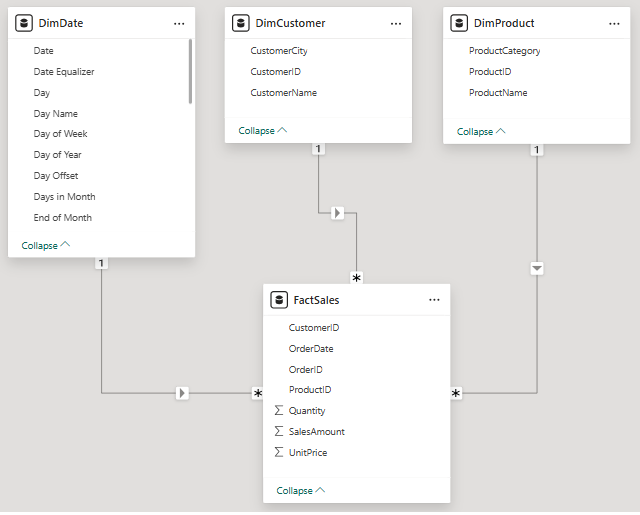
Create Relationships: Power BI might automatically detect some relationships (depending on settings), but always verify or create them manually.
Drag the primary key from each dimension table (e.g., DimCustomer[CustomerID]) to its corresponding foreign key in the fact table (e.g., FactSales[CustomerID]).
Confirm that the relationships are correctly set to "One-to-Many" (from the dimension to FactSales) and the cross-filter direction is "Single" (from the dimension to FactSales). This allows filters applied to your dimensions to flow down and filter your fact data.
Your Optimized Power BI Model Awaits!
And just like that, you've successfully transformed your denormalized data into an efficient Power BI star schema. By creating dimension and fact tables and optimizing Power Query loads, you've built a robust model that is optimized to improve performance and usability.
Sign up to receive our bimonthly newsletter!
Not sure on your next step? We'd love to hear about your business challenges. No pitch. No strings attached.